
Non è un argomento nuovo ma è decisamente attuale. Si parlava di Data poisoning già nei primi anni del 2000 ma il proliferare dei Big data e l’evoluzione delle Intelligenze artificiali lo rimettono al centro del dibattito con tutte le preoccupazioni che si porta appresso.
Il Data poisoning è uno ma ha diverse declinazioni e, soprattutto ha due effetti principali che concorrono a renderlo una minaccia temibile. Ridurre il rischio è possibile, anche se escluderlo del tutto è pressoché proibitivo, proprio perché i dati necessari a una qualsiasi organizzazione tendono ad avere origine fuori dai perimetri della rete aziendale.
Cyber attacchi: aziende italiane nel mirino, settore sanitario fuori dai radar e a maggior rischio
Indice degli argomenti
Il Data poisoning
Le Intelligenze artificiali e il Machine learning sono esposte al rischio di Data poisoning, ovvero un attacco perpetrato modificando i dati oppure iniettando nei dataset delle informazioni manomesse che verranno poi usate per addestrare i modelli di Machine learning.
Un attacco che ha due conseguenze catastrofiche: la prima è la riduzione drastica dell’affidabilità dei modelli e la seconda, non da escludere a priori, è quella di permettere agli aggressori di aggiungere una backdoor che consente di indurre i modelli a fare ciò che essi desiderano.
Come detto, il Data poisoning ha diverse declinazioni possibili. Partendo dal presupposto che i modelli di Machine learning possono trovare correlazioni tra set di dati enormi, emerge in modo preponderante l’aspetto secondo cui, modificando le informazioni, il lavoro delle Intelligenze artificiali intese come costrutto può essere messo a rischio.
Del resto il Machine learning arriva a trovare parallelismi che l’uomo osserverebbe impiegando molto più tempo ma, al contrario dell’essere umano, sono del tutto privi di rigori logici.
Uscendo dagli ambiti aziendali e ipotizzando un avvelenamento dei dati nelle applicazioni usate nel mondo della sanità, la potenza della deflagrazione del Data poisoning risulta ancora più comprensibile. Correlazioni tra dati inattendibili, diagnosi fuori luogo, costi a carico della socialità e crisi del sistema sanitario.
Per evitare di credere che questo scenario sia eccessivo basta rifarsi a uno studio del 2018, grazie al quale, è stato dimostrato che un errore di addestramento dei modelli di Machine learning ha indotto un sistema a diagnosticare melanomi laddove non ce n’era invece traccia.
Oppure, avvelenando i dati, si possono compromettere i cicli di addestramento delle automobili a guida autonoma, inducendole a credere che un segnale stradale abbia un significato diverso da quello reale. Il problema nasce quando un limite di velocità viene male interpretato oppure un obbligo di dare la precedenza viene tramutato in un via libera.
Riducendo la portata del Data poisoning e sottolineando quanto sia facile ingannare un’Intelligenza artificiale, basti pensare a quegli indumenti che rendono impossibile il riconoscimento facciale di chi li indossa. Il principio è il medesimo dell’avvelenamento dei dati: informazioni impercettibili agli occhi che però riducono l’efficacia delle Intelligenze artificiali.
La mitigazione del rischio
Come sempre accade in tema di cyber security, escludere i pericoli è impossibile ma mitigarli è doveroso e, in qualche modo, è l’essenza stessa della sicurezza la quale – non a caso – si muove anche nella direzione delle tecniche predittive il cui obiettivo primario è quello di scandagliare sistemi e architetture alla ricerca di vulnerabilità.
Allo stesso modo, uno dei fondamenti della cyber security è avere un’elevata consapevolezza delle minacce e questo vale anche per il Data poisoning: prima di potere creare strategie efficaci per proteggere i sistemi di Machine learning, è necessario capire in cosa consiste l’avvelenamento dei dati e quali sono le sue conseguenze.
Obiettivo consapevolezza
Continuando a ragionare per similitudini, occorre considerare i rapporti tra presente e passato. Per questo motivo è opportuno esaminare i set di dati facendo leva su modelli di Machine learning precedentemente usati rispetto a quelli attualmente in produzione.
Se questi dovessero restituire risultati differenti da quelli che hanno fornito, quando erano a loro volta i modelli produttivi, c’è il rischio che nel frattempo i dati siano stati alterati.
Andando a ritroso, occorrono politiche per limitare la quantità di dati che può essere fornita da un singolo utente.
Di norma gli aggressori iniettano grandi quantità di dati nei dataset e se questo diventa impossibile proprio perché le policy interne lo impediscono, il raggio di azione si riduce di molto e può essere maggiormente contenuto applicando i controlli degli accessi e rafforzando le politiche di identificazione ai client e ai server (anche ai servizi in Cloud) dediti alla raccolta e all’analisi dei dati.
Nel 2021, Hyrum Anderson di Microsoft ha illustrato come sia possibile ottenere informazioni da un modello Machine learning senza essere rilevati dai sistemi di difesa e, nel medesimo video, ha mostrato come sferrare un attacco.
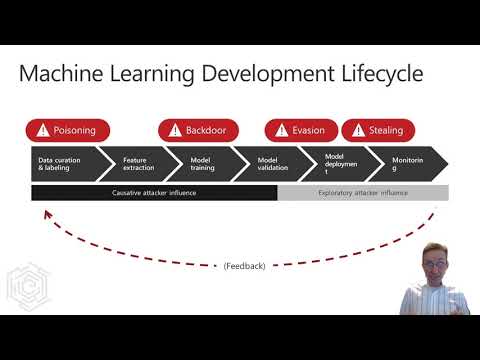
Una performance che dovrebbe fare scuola perché offre – in una ventina di minuti – un’ampia visuale sui rischi a cui le imprese sono potenzialmente esposte e perché suggerisce in quale direzione muoversi per scongiurare il pericolo.
Le tecniche di difesa
A tutto ciò devono essere affiancate tutte le tecniche e le tecnologie che consentono di ridurre la superficie di attacco, tra firewall, applicazione costante e immediata delle patch di sicurezza, il monitoraggio del traffico di rete e un piano di risposta agli incidenti.
Non da ultimo occorre tenere in debito conto anche la sicurezza fisica perché l’avvelenamento dei dati può avvenire anche all’interno delle mura aziendali.
Tutto questo è certamente impegnativo e, oltre a rappresentare un costo, rallenta in modo sensibile l’estrazione di valore dai dati. Pulire i dati avvelenati è più complesso, richiede maggiore impegno e rende potenzialmente del tutto inutili le attività di addestramento delle Intelligenze artificiali.












