
Il backup dei dati rappresenta la prima politica informatica anche nel piano di Disaster Recovery per salvaguardare i dati utilizzati all’interno del processo produttivo, in modo da eseguirne l’eventuale ripristino in caso di necessità.
Ad esempio in seguito a un attacco ransomware: è necessario progettare una soluzione ottimale che sia un giusto compromesso tra i dispositivi hardware e i software presenti nell’infrastruttura ICT e il potenziale economico aziendale in termini di budget da destinare alla salvaguardia delle informazioni aziendali.
Una delle soluzioni software che ci consente di eseguire il salvataggio dei dati in modo professionale ma nello stesso tempo economico è il tool rsync da remote synchronization.
Indice degli argomenti
Cos’è rsync e perché usare questo software per il backup in remoto
rsync è un tool gratuito rilasciato sotto licenza GNU GPL che consente attraverso la programmazione da riga di comando (ed eventualmente inserito in uno script) di effettuare in modo snello (anche in termini di manutenzione nel caso sia necessaria la modifica della configurazione dei device interessati nel processo di salvataggio dei dati) il backup dei dati sincronizzando i file e le cartelle di interesse tra la directory sorgente e la directory di destinazione sia in locale che in remoto sotto sistemi Linux.
rsync sostituisce i comandi cp e scp realizzando il mirroring (copia specchiata) dei dati ed eseguendo in modo ottimale il trasferimento incrementale dei file inviando solo quelli presenti nell’host sorgente diversi (o assenti) nell’host destinazione.
Altra caratteristica che lo rende ideale per eseguire copie di backup in remoto è l’integrazione pressoché perfetta con il protocollo SSH (Secure SHell) che consente la creazione di una sessione remota cifrata sostituendo l’insicuro protocollo Telnet.
Prerequisiti per creare un sistema di backup con rsync
- competenze ICT (utilizzate negli esempi di programmazione successivi):
- conoscenze basilari di amministrazione della piattaforma Linux (negli articoli successivi risulterà importante anche la conoscenza del sottosistema Windows per Linux WSL);
- conoscenze basilari sulle Reti Locali e Remote;
- conoscenze basilari per eseguire l’accesso attraverso SSH;
- Hardware e Software:
- almeno due macchine (è preferibile usare macchine virtuali per effettuare tutte le prove possibili prima di passare alle macchine reali) dove è presente la distribuzione Linux. L’architettura di sistema per le macchine virtuali è AMD64 con 1 CPU, RAM 4 GB e 20 GB di hard disk, mentre per il computer ospitante le Macchine Virtuali suggeriamo almeno 8 GB di RAM e un disco SSD da 240GB;
- essere in grado di accedere come root sul computer sorgente e attraverso SSH sul computer destinazione.
Come installare rsync
Prima di procedere all’installazione di rsync, è consigliato aggiornare il nostro sistema operativo, digitando il seguente comando:
sudo apt update && sudo apt upgrade
Al termine dell’aggiornamento, potremo procedere all’installazione di rsync utilizzando il comando:
sudo apt install rsync
Per installare rsync su Red Hat e derivate si utilizzeranno i comandi
yum update -y
yum install rsync -y
Sintassi e opzioni per installare rsync
Per sfruttare al massimo le caratteristiche di rsync ne analizziamo la sintassi:
rsync [opzioni] SORGENTE DESTINAZIONE
Per ottenere informazioni su rsync ci affideremo all’helper, richiamandolo con -h:
rsync -h
In particolare, potremo ottenere dettagli sulle numerose opzioni disponibili.
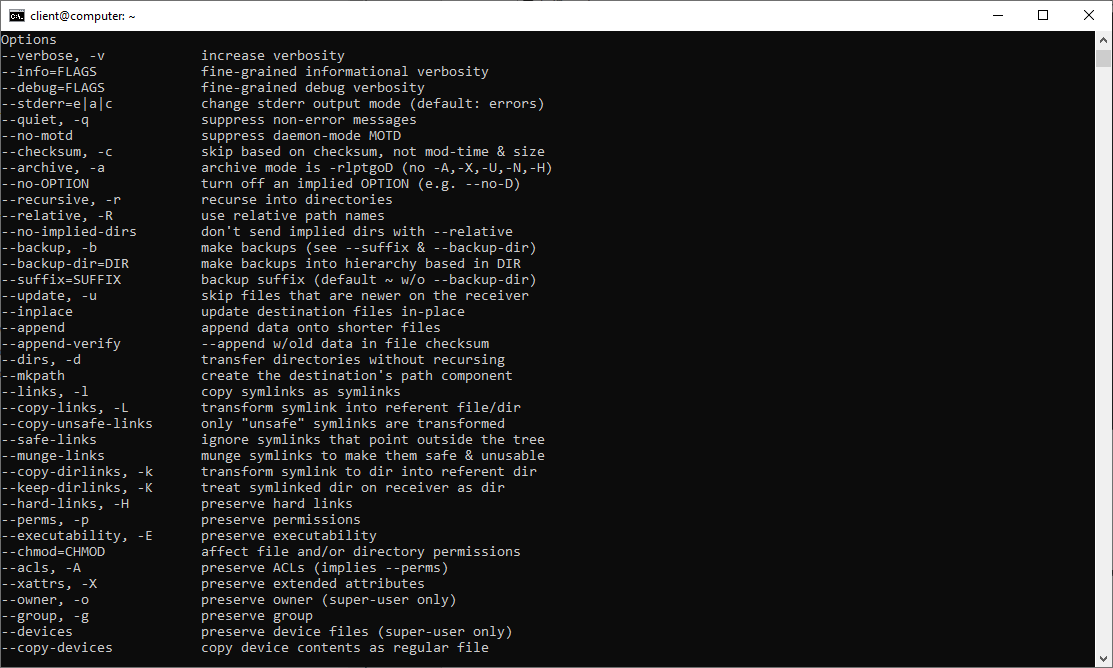
Analizziamo le opzioni più utilizzate:
- r copia ricorsiva (non include gli attributi dei file)
- a crea un archivio dei file, compresi gli attributi dei file
- v mostra a schermo il dettaglio delle operazioni
- h rende i valori mostrati in output più facili da leggere per l’utente
- P mostra lo stato di avanzamento della fase di copia e indica a rsync di mantenere i file trasferiti parzialmente (di default vengono invece cancellati)
- q modalità silente
- z attiva la compressione dei file
Come effettuare un backup in una cartella locale
Nel nostro primo esempio, creeremo una copia specchiata di una cartella in una directory locale denominata “origine” all’interno della cartella denominata “destinazione”. rsync è in grado di creare autonomamente nuove directory di destinazione.
Utilizzeremo le opzioni –av, abilitando quindi la modalità archivio (copia ricorsiva dei file e degli attributi) e richiedendo al programma di mostrarci informazioni sulla copia dei file.
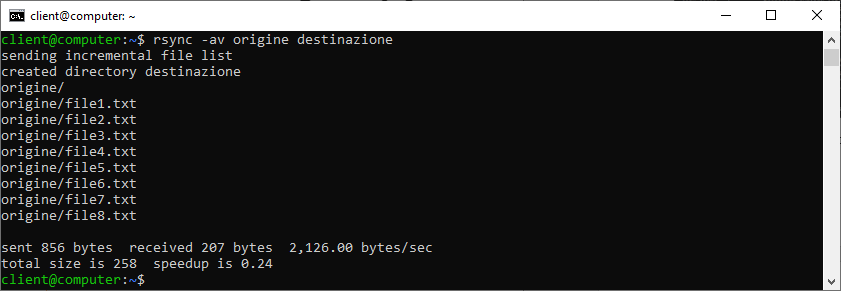
rsync -av origine destinazione
N.B. Con il comando lanciato copieremo l’intera cartella “origine” in “destinazione”. Per copiare esclusivamente i contenuti della cartella, dovremo apporre il simbolo / alla fine del nome della cartella sorgente, quindi rsync -av origine/ destinazione.
rsync crea delle copie incrementali. Se lanciassimo nuovamente il comando, non verrebbe copiato alcun file.
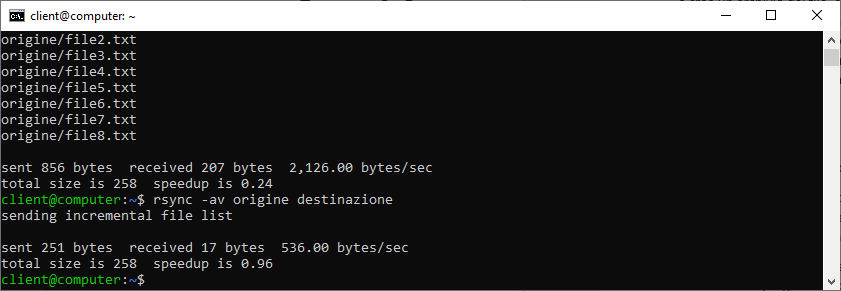
Modificando invece uno dei file presenti all’interno della cartella “origine”, solo questo verrà aggiornato nella fase di copia. Ad esempio, cambiando il contenuto del file “file8.txt” e lanciando nuovamente il comando, noteremo che solo il documento modificato verrà aggiornato.
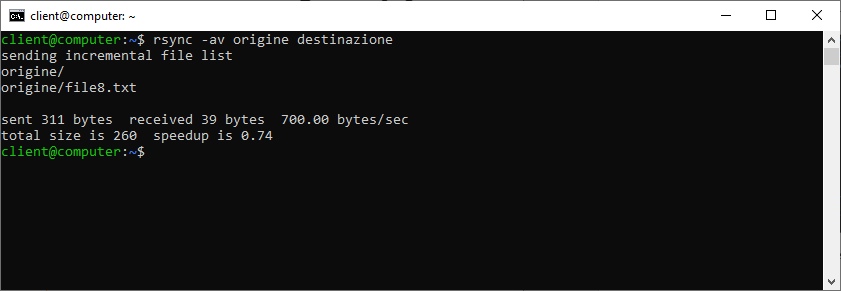
Come detto ad inizio paragrafo, l’intendo di questo primo esempio è creare una copia specchiata: il contenuto delle cartelle “origine” e “destinazione” dovrà quindi essere uguale. Questo comporta che se un file viene rimosso da “origine”, questo dovrà essere cancellato anche da “destinazione”. Proviamo quindi a rimuovere “file8.txt” da “origine” e lanciamo nuovamente il comando rsync.
Il file non è stato rimosso da “destinazione” rendendo quindi i contenuti delle due cartelle non specchiate.
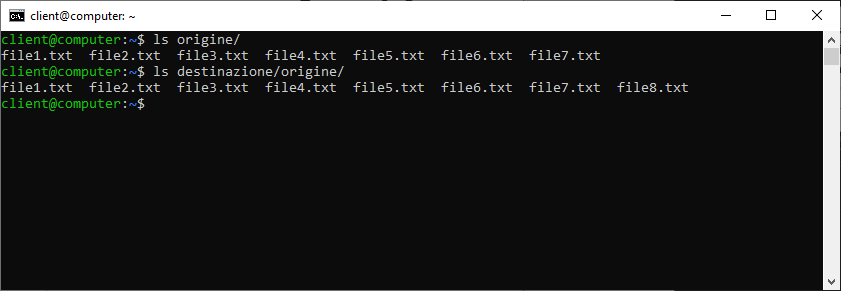
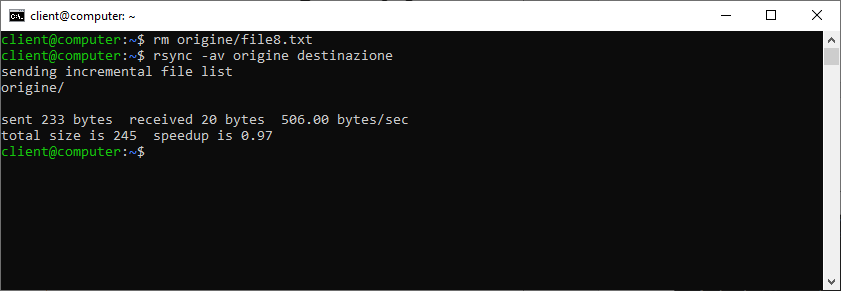
Per creare una vera copia specchiata dovremo aggiungere, al nostro comando l’opzione –delete, indicando quindi a rsync di rimuovere tutti i file presenti della cartella d’origine. Lanciamo quindi il comando:
rsync -av –delete origine destinazione
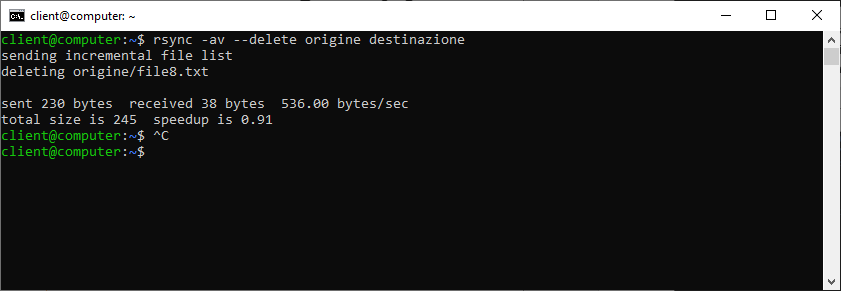
Il file precedentemente cancellato da “origine” è ora stato rimosso anche in “destinazione”.
Come effettuare un backup in una cartella remota
Una delle regole base del backup è salvare le copie di sicurezza in dispositivi di archiviazione diversi da quelli in cui sono presenti i dati di origine, in modo da prevenirne la perdita in caso di malfunzionamenti del drive.
Ora vedremo come effettuare una copia dei nostri dati su un host remoto.
rsync consente la sincronizzazione di dati tra macchine diverse attraverso il protocollo SSH (Secure Shell). La sintassi del comando è la seguente:
rsync [opzioni] SORGENTE Utente_SSH@Indirizzo_IP_HOST:DESTINAZIONE
Su entrambe le macchine dovrà essere installato OpenSSH e rsync.
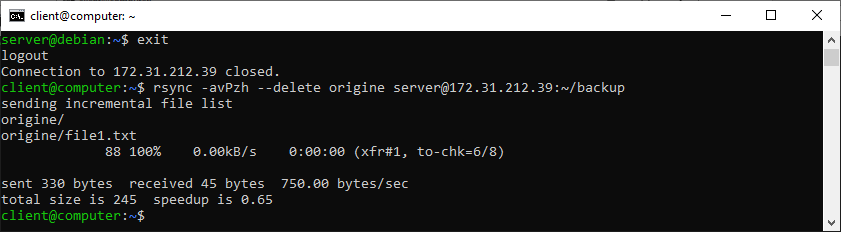
Andremo quindi a copiare la cartella “origine” su un host con indirizzo IP 172.31.212.39, utilizzando l’utente server. I file verranno archiviati nella directory ~/backup.
In questo caso, alle opzioni -av –delete viste nell’esempio precedente, aggiungeremo anche:
- -P per ottenere maggiori informazioni sulla copia;
- -h per rendere i valori mostrati facilmente fruibili dall’utente;
- -z per comprimere i file trasferiti e alleggerire così il carico di lavoro della rete.
N.B. Prima di avviare la procedura di backup, assicurarsi che lo spazio di archiviazione del dispositivo di destinazione sia abbastanza capiente da contenere i file trasferiti.
Il comando da lanciare sarà, quindi:
rsync -avPzh –delete origine server@172.31.212.39:~/backup

I file saranno così copiati all’interno della sottocartella backup presente nella cartella home dell’host.
Abbiamo visto come inviare file da un computer client ad un host remoto. Andremo ora ad effettuare il procedimento inverso, prelevando i dati dal computer che usiamo da server. In questo caso inseriremo come sorgente la cartella dell’host remoto e come destinazione la directory home.
rsync -avPzh –delete server@172.31.212.39:~/backup ~
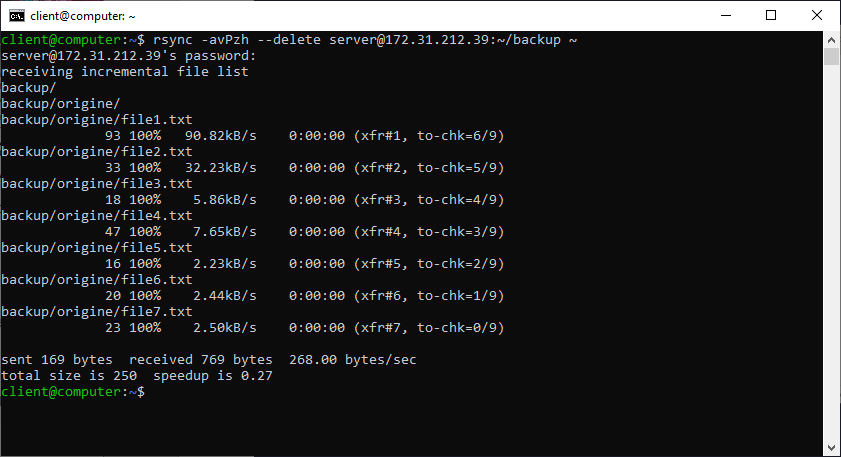
N.B. Il simbolo ~ (Tilde) indica il percorso /home/NOME_UTENTE e, in questo esempio, equivale a scrivere.
rsync -avPzh –delete server@172.31.212.39:~/backup /home/client
Ogni volta che tentiamo di avviare una procedura di backup da remoto, ci verrà richiesta la password dell’utente SSH utilizzato. Nonostante questa sia una corretta politica di sicurezza, non consente di creare una procedura di backup pianificata. Per eludere questa problematica sarà quindi necessario creare una chiave di autentificazione pubblica sul computer client e aggiungerla al file “authorized_keys” dell’host remoto.
Per generare la coppia di chiavi SSH lanciamo il comando:
ssh-keygen -t rsa -b 4096
Manteniamo le configurazioni di default (premendo il tasto “invio”) e non impostiamo alcuna password.
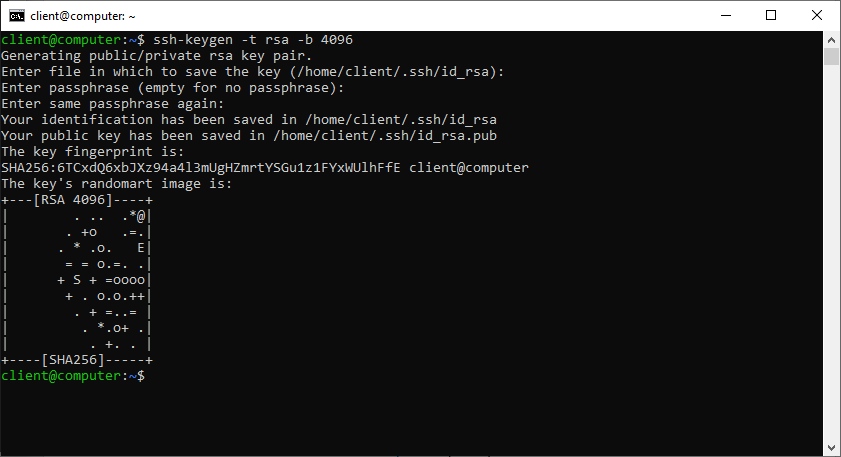
Le chiavi saranno archiviate nella directory nascosta ~/.ssh/.
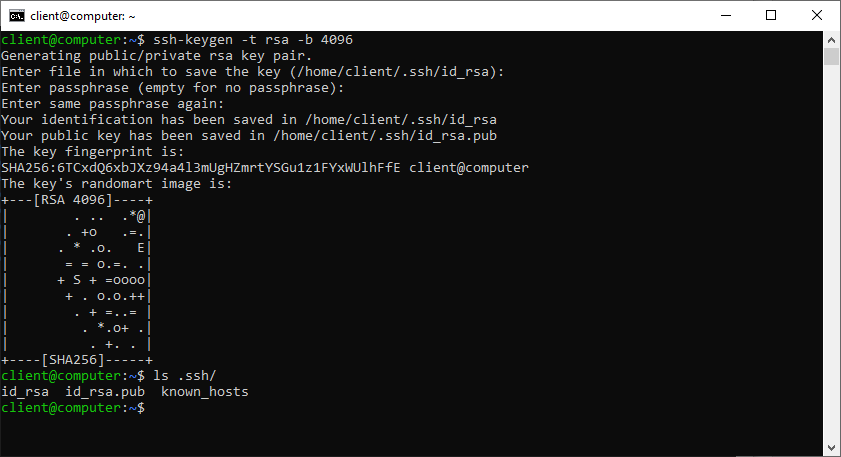
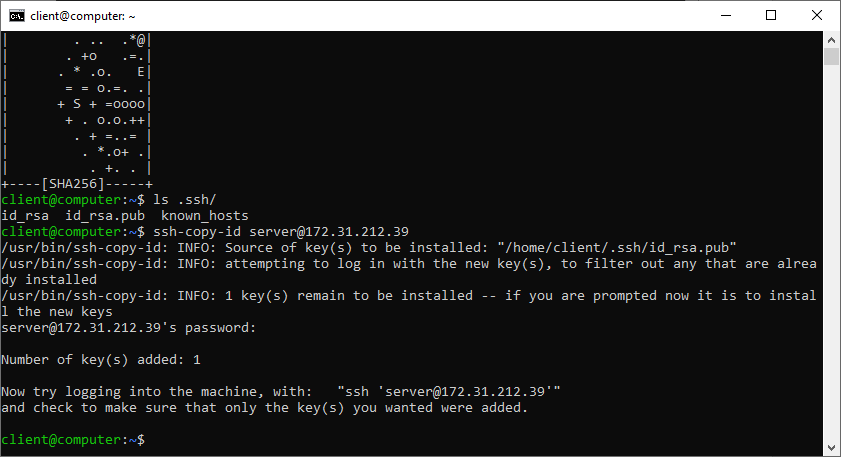
Dovremo ora inviare la chiave pubblica appena creata (id_rsa.pub) all’host remoto. Utilizzeremo il comando ssh-copy-id, indicando l’utente ssh e l’indirizzo del server:
ssh-copy-id server@172.31.212.39
Dopo aver inserito la password di accesso, la chiave pubblica sarà aggiunta al file authorized_keys dell’utente remoto.
Proviamo a collegarci, in SSH, al computer remoto: se la procedura è stata svolta correttamente, non dovrebbe essere richiesta nessuna password.
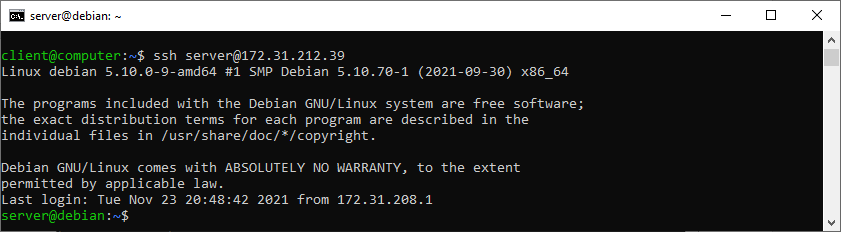
La procedura di backup ora non sarà interrotta dalla richiesta dell’immissione di una password.
Pianificare una procedura di backup con rsync
Per pianificare l’esecuzione delle nostre procedure utilizzeremo cron, creando nel crontab un job in cui indicheremo il comando da eseguire e la sua schedulazione.
Apriamo il file crontab lanciando il comando:
crontab -e

Al primo avvio di crontab ci verrà chiesto di indicare quale editor di testo utilizzare (in questo esempio, nano).
Visualizzeremo il file di configurazione. Scorriamolo fino alla fine, in modo da poter inserire la pianificazione della nostra procedura di backup e il comando.
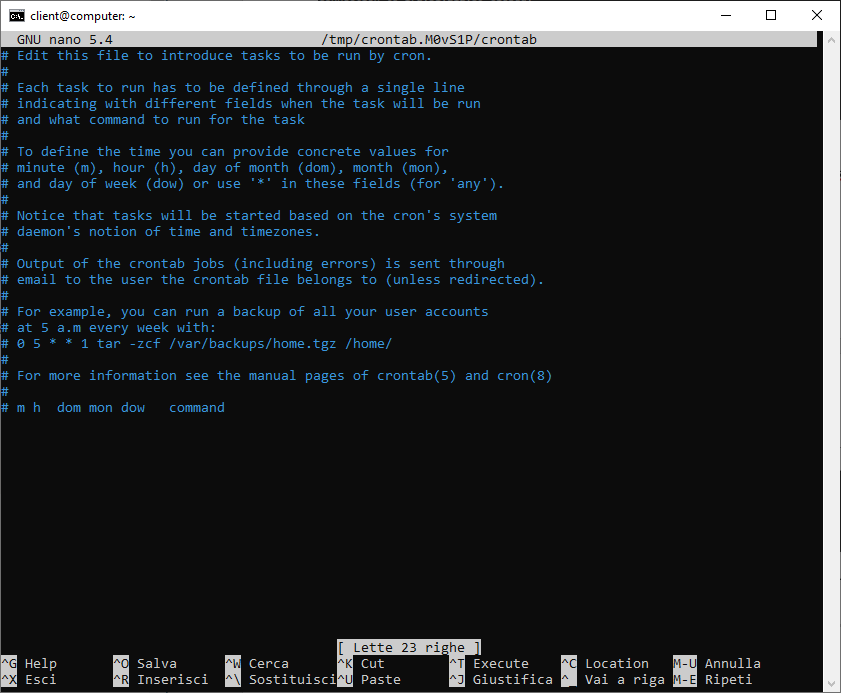
Ogni riga del crontab conterrà una schedulazione.
Per configurare la schedulazione avremo a disposizione 5 campi, divisi da uno spazio, in cui potremo indicare:
Minuti (0-59)
Ore (0-23)
Giorno del mese (1-31)
Mese (1-12)
Giorno della settimana (0-7)
Potremo utilizzare gli operatori:
- , per indicare una lista di valori
- – per indicare un intervallo di valori
- * per indicare tutti i valori disponibili per il camp
- / per saltare dei valori.
Dopo aver indicato la schedulazione, potremo inserire il comando (o il file) da eseguire.
Dato che l’operazione è pianificata, non avremo necessità di visualizzare informazioni sulla fase di copia. Utilizzeremo quindi l’opzione -q (modalità silente) rimuovendo invece -Pvh.
Ad esempio, se vogliamo lanciare il nostro comando di backup ogni lunedì alle ore 15, aggiungeremo il job:
* 15 * * 1 rsync -aqz –delete origine server@172.31.212.39:~/backup
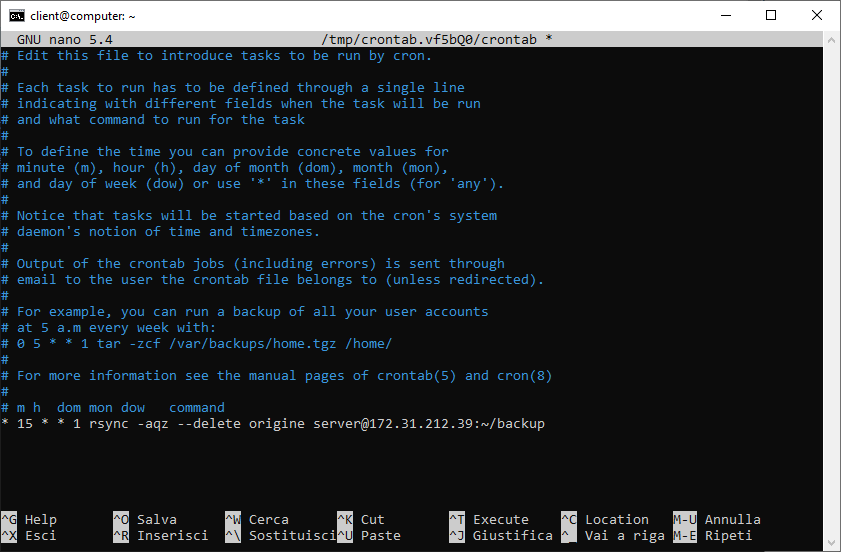
Salviamo il file e chiudiamolo. Un messaggio di output ci confermerà la corretta installazione del nuovo job.
Storage del backup su Cloud
rsync non supporta direttamente i servizi di cloud storage. Per questo è possibile utilizzare strumenti o script aggiuntivi per montare il servizio di cloud storage come un filesystem locale (ad esempio, utilizzando rclone o simili).
In questo modo, si può sfruttare la potenza e la flessibilità di rsync per gestire i dati su Cloud, automatizzando processi di backup e sincronizzazione.
pCloud: il Cloud rigoroso
⚡ Velocità upload: Molto veloce
🔄️ Accesso ai file offline: ✔️
💰 Costo: 199 € (a vita)
📱 Mobile: Android, iOS
💻 Desktop: Windows, Linux, macOS
🔐 Sicurezza: TLS/SSL 256-AES
🧑💻 Facilità di utilizzo: Molto facile
🔥 Offerte attive: SCONTO fino al 37%
pCloud è un servizio di cloud storage. Si utilizza il cloud come se fossero salvati localmente ma senza occupare spazio sul tuo hard disk.
Caratteristiche e vantaggi di pCloud:
- File protetti dalle leggi svizzere che sono le più rigorose per i dati personali, poiché l’azienda ha sede in Svizzera;
- Conserva facilmente, sincronizza e accedi ai tuoi file su un’unità sicura: i file sono accessibili anche offline;
- Con pCloud sei sempre a un clic di distanza dal liberare più spazio sul telefono salvare file direttamente dal web o sincronizzare tutti i tuoi file;
- pCloud utilizza la crittografia TLS/SSL. Inoltre, puoi usare pCloud come una cassaforte per password, rapporti finanziari e altri file confidenziali;
- Condividi file di grandi dimensioni, invita amici e permetti ai compagni di squadra di aggiungere file senza vedere il contenuto delle tue cartelle, anche se non hanno pCloud.
pCloud offre diverse opzioni di piani di archiviazione cloud, sia con abbonamenti mensili/annuali che con licenze a vita. Offre anche un piano gratuito con fino a 10 GB di spazio di archiviazione ed è possibile aggiungere la funzione di crittografia per una maggiore sicurezza dei dati.
Internxt: Cloud attento alla privacy

⚡ Velocità upload: Molto veloce
🔄️ Accesso ai file offline: ✔️
💰 Costo: da 0,99 €/mese
📱 Mobile: Android, iOS
💻 Desktop: Windows, macOS
🔐 Sicurezza: TLS/SSL 256-AES
🧑💻 Facilità di utilizzo: Molto facile
🔥 Offerte attive: SCONTO del 50% sui piani a vita
Internxt è un servizio di cloud storage sicuro e incentrato sulla privacy nato come ai grandi colossi del cloud (come Google Drive, Dropbox o OneDrive). A differenza di molte soluzioni tradizionali Internxt utilizza la crittografia end-to-end e un’architettura decentralizzata in cui i file vengono frammentati, crittografati e distribuiti su più server per massimizzare la sicurezza e ridurre i rischi di violazione.
Caratteristiche principali:
- Crittografia Zero-Knowledge: solo l’utente può accedere ai suoi file. Nemmeno Internxt ha accesso ai contenuti;
- Archiviazione sicura in cloud: per documenti, foto, video e file di qualsiasi tipo;
- Piattaforme supportate: disponibile su web, desktop (Windows, macOS, Linux) e mobile (iOS, Android).
I servizi offerti:
- Internxt Drive: l’equivalente di Google Drive;
- Internxt Photos: per conservare e organizzare foto con crittografia totale;
- Internxt Send: per condividere file crittografati in modo sicuro;
- Nuovi servizi integrati: VPN, Antivirus, Mail e Meet.
Internxt non vende i dati degli utenti. Ha sede e infrastrutture nell’Unione Europea, soggette al GDPR. È un servizio ideale per professionisti, attivisti, aziende attente alla privacy e utenti che non vogliono compromettere la riservatezza dei propri dati.
Abbiamo illustrato come creare la base per il backup dei nostri dati sotto sistemi Linux, in modo da non andare in ufficio di sabato per verificare se tutto è stato effettuato correttamente o controllare se la versione del file è aggiornata o no, e tanto meno stare con l’ansia se c’è qualche disastro in ufficio e i dati saranno distrutti.













































































